
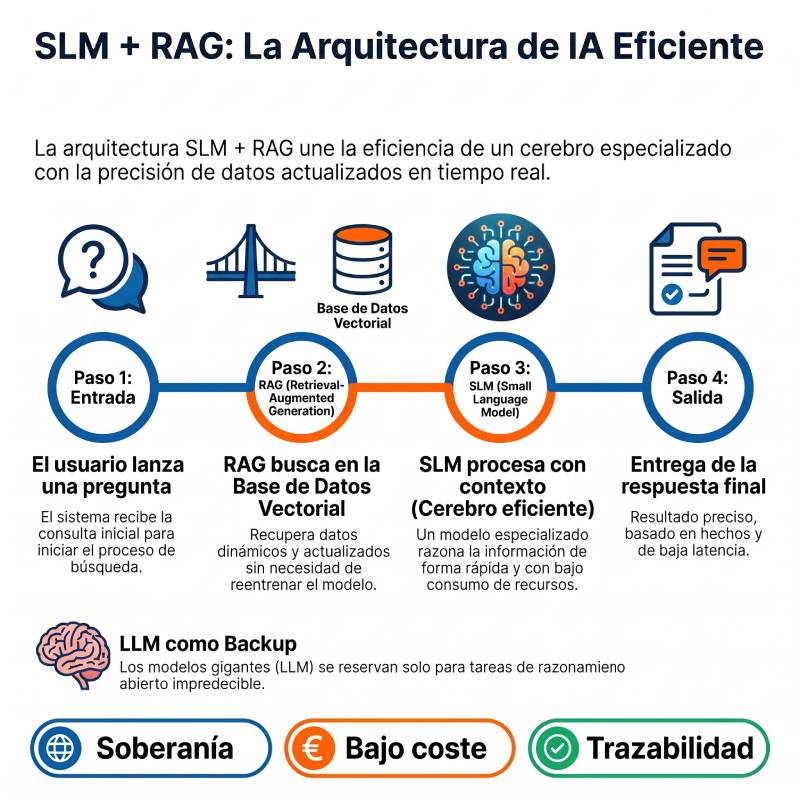
La pregunta que de verdad importa en la IA empresarial no es «¿modelo grande o pequeño?», sino «¿qué arquitectura?». Y para el grueso del trabajo real, la respuesta no es un único componente: es una combinación de un modelo pequeño y especializado (SLM) con recuperación de información (RAG), dejando el modelo gigante (LLM) para la minoría de casos que de verdad lo necesitan. Esa decisión —no la elección de un modelo aislado— es la que define tu coste, tu precisión y tu soberanía sobre el dato.
Conviene empezar deshaciendo una confusión muy extendida.
Contenidos
- Dos respuestas al mismo problema, que no son lo mismo
- Qué es un SLM
- Qué es RAG
- SLM vs RAG: la comparación que aclara la decisión
- El error es verlos como rivales: son complementarios
- Por qué esta arquitectura define tu margen
- Cuándo elegir cada pieza
- Cómo se compone con el dato propietario (el foso)
- Conclusión
Dos respuestas al mismo problema, que no son lo mismo
Los LLM tradicionales son potentes, pero caros de operar y propensos a «alucinar». Frente a esa limitación surgieron dos aproximaciones que mucha gente confunde, cuando en realidad atacan ejes distintos:
- El SLM cambia el tamaño del modelo.
- El RAG cambia la forma en que el modelo accede a la información.
No compiten. Resuelven problemas diferentes. Y, como veremos, funcionan mejor juntos.
Qué es un SLM
Un SLM (Small Language Model) es un modelo de lenguaje entrenado con muchos menos parámetros que un LLM —típicamente entre 1.000 y 10.000 millones, frente a los más de 100.000 millones de un modelo gigante—, centrado en la eficiencia de cómputo y en la especialización en un dominio mediante datos de alta calidad. Ejemplos: Phi (Microsoft), Llama (Meta), Gemma (Google).
Su conocimiento queda congelado en sus pesos tras el entrenamiento: es estático. A cambio, consume muy poca memoria, se ejecuta de forma nativa en local y tiene baja latencia. Para actualizarlo hay que reentrenarlo (fine-tuning).
Qué es RAG
RAG (Retrieval-Augmented Generation) no es un modelo, es una arquitectura. Consiste en conectar un modelo de lenguaje —sea LLM o SLM— a una base de datos externa (normalmente vectorial) para buscar información en tiempo real antes de generar la respuesta. Su conocimiento es dinámico: se actualiza añadiendo o editando un documento, sin reentrenar nada.
Su gran virtud es la trazabilidad: al inyectar las fuentes en el prompt, reduce drásticamente las alucinaciones y permite auditar de dónde sale cada respuesta.
CASO DE ÉXITO
Cómo Novo Nordisk activó la formación del equipo de ventas mediante Gamificación

SLM vs RAG: la comparación que aclara la decisión
| Criterio | SLM (Small Language Model) | RAG (Retrieval-Augmented Generation) |
|---|---|---|
| Naturaleza | Un modelo de IA compacto y optimizado | Una arquitectura / patrón de diseño |
| Fuente de conocimiento | Estática (congelada en los pesos) | Dinámica (base de datos en tiempo real) |
| Memoria / RAM | Muy baja (ideal para local o VPS modesto) | Variable (según modelo base y motor de vectores) |
| Precisión en datos internos | Moderada (puede olvidar detalles en dominios enormes) | Muy alta (accede al documento original) |
| Privacidad / soberanía | Excelente (100% local nativo) | Excelente (si la BD vectorial y el modelo son locales) |
| Coste de actualización | Requiere fine-tuning (reentrenamiento ligero) | Inmediato (añadir o editar un documento en la BD) |
El error es verlos como rivales: son complementarios
Aquí está el punto que cambia el diseño. Las debilidades de uno son, casi exactamente, las fortalezas del otro:
- El SLM tiene conocimiento estático y puede alucinar sobre lo que no está en sus pesos. RAG lo resuelve: le da acceso en tiempo real a la información correcta y auditable.
- RAG necesita un modelo que genere la respuesta. El SLM lo aporta barato: un modelo pequeño, rápido y desplegable en local.
La conclusión técnica es directa: para la mayoría de los casos empresariales, la arquitectura no es «SLM o RAG», es «SLM + RAG». Un modelo pequeño y especializado que razona con eficiencia, alimentado por un sistema de recuperación que le entrega los datos correctos en cada momento. El LLM gigante queda como respaldo para la minoría de tareas de razonamiento abierto.
Por qué esta arquitectura define tu margen
Cuando tu producto se apoya en un LLM vía API, tu coste de servir cada interacción depende del precio que fije un tercero, y de hecho el coste de inferencia cayó alrededor de un 80% entre 2023 y 2025, lo que fue letal para las empresas cuyo único foso era el diferencial entre coste y precio.
La arquitectura SLM + RAG invierte esa dependencia por dos vías:
- El SLM controla el coste y la soberanía. Su inferencia puede salir entre 10 y 30 veces más barata que la de un LLM equivalente, y se despliega on-premise. Dejas de ser rehén del pricing del proveedor. Y como el paper de NVIDIA de 2025 documentó que entre el 70% y el 90% del trabajo es repetitivo y acotado —Gartner prevé para 2027 tres veces más despliegue de modelos especializados que de LLM—, ese grueso lo asume el modelo pequeño sin pérdida.
- El RAG controla el coste de mantener el conocimiento al día. Actualizar no exige reentrenar: basta con editar un documento en la base de datos. Y su ventana de contexto es eficiente: no satura el modelo con datos irrelevantes, solo le entrega lo necesario para la pregunta actual.
El segundo efecto, estratégico: el footprint pequeño del SLM y una base vectorial local permiten desplegar todo el sistema on-premise. En banca, seguros o farmacia, donde el dato sensible no puede salir, eso no es un detalle técnico, es la condición de entrada.
Cuándo elegir cada pieza
- Elige SLM si automatizas tareas lógicas puras (clasificación, formateo de datos, asistencia de código en local), necesitas latencia mínima o despliegas en hardware limitado.
- Elige RAG si tu prioridad es la fidelidad del dato, trabajas con miles de páginas de documentación interna que cambia constantemente, o necesitas citar fuentes reales de forma auditable.
- Combina SLM + RAG para el caso general: la eficiencia y especialización del modelo pequeño, más la fidelidad y la actualidad de la recuperación.
- Reserva el LLM para el razonamiento abierto e impredecible, como respaldo.
Cómo se compone con el dato propietario (el foso)
Esta arquitectura es, además, donde el dato propietario se convierte en ventaja. RAG sobre la base de conocimiento propietaria (dato conductual, de cliente y de producto) + SLM afinado sobre el dato de comportamiento. El SLM aporta el «cómo se cambia un comportamiento», destilado de años de programas; RAG aporta el dato vivo, específico y auditable de cada cliente. El resultado es un sistema barato, especializado, on-premise, actualizado y trazable. Y, sobre todo, defendible: ni un chatbot genérico ni una capa fina sobre un LLM tienen el modelo afinado ni la base de conocimiento.
Conclusión
Deja de preguntar «¿qué modelo?». Pregunta «¿qué arquitectura?». Para el grueso del trabajo: SLM + RAG, con el LLM como respaldo, todo sobre dato propietario. Esa combinación da las cuatro cosas a la vez —margen, fidelidad, soberanía y foso— que ningún componente aislado consigue.
CONTACTA
Contacta con nosotros y descubre cómo podemos ayudarte en tu próxima gamificación

¿Qué es mejor, un SLM o RAG?
Ninguno es «mejor»: no compiten, resuelven problemas distintos. El SLM cambia el tamaño del modelo (eficiencia, especialización, ejecución local); RAG cambia cómo el modelo accede a la información (datos en tiempo real, auditables). En la mayoría de los casos empresariales rinden mejor combinados que por separado.
¿SLM y RAG son lo mismo?
No. Un SLM es un modelo de lenguaje pequeño y especializado; RAG (Retrieval-Augmented Generation) es una arquitectura que conecta un modelo —SLM o LLM— a una base de datos externa para recuperar información antes de responder. Uno es el «cerebro»; el otro, la forma de darle acceso a la información correcta.
¿Se puede combinar un SLM con RAG?
Sí, y es la combinación recomendada para el caso general. El SLM razona de forma barata y en local, y RAG le entrega datos actualizados y auditables en tiempo real. La debilidad del SLM (conocimiento estático) la cubre RAG; la necesidad de un modelo que tiene RAG la cubre el SLM de forma económica.
¿Cuándo conviene usar RAG en lugar de fine-tuning?
RAG es preferible cuando el conocimiento cambia con frecuencia o debe poder citarse de forma auditable, porque actualizarlo solo requiere editar un documento. El fine-tuning es preferible para especializar el comportamiento del modelo en una tarea estable. No son excluyentes: lo habitual es afinar el SLM y, además, darle RAG sobre la base de conocimiento.
¿Qué es RAG (Retrieval-Augmented Generation)?
Es una arquitectura que conecta un modelo de lenguaje a una base de datos externa (normalmente vectorial) para buscar información relevante en tiempo real antes de generar la respuesta. Reduce las alucinaciones, permite citar fuentes y mantiene el conocimiento actualizado sin reentrenar el modelo.




